
If you found the title interesting (hence you are reading this) you most likely know what a convolution is. It’s a crucial computation piece that you want to ensure is efficiently implemented. For this reason, there are plenty of libraries, implementations, and even hardware extensions designed to enhance convolution speed. But have you ever considered just how much faster it can be? How slow is the naïve implementation? And how much can compiler optimization aid? Here, I attempt to showcase speed comparisons on the de facto standard computer of a hardware enthusiast: the Raspberry Pi.
In this post, I test 2D convolution applied to image data as I am interested in processing camera streams directly on a Raspberry Pi. This is a tricky thing, primarily because convolution takes a lot of time, and smoothly processing images from the camera at 30fps leaves little room for flexibility. In practice, the convolution of the famous Lena picture with a kernel would look as follows:

The kernel size was 3×3. While the content of the kernel does not influence the speed, in this particular case the kernel looked like this:

The platform
Raspberry Pi 5 is the latest addition to the popular single-board computer lineup. In the era of AI, many people will want to run deep models on the device. As the most powerful raspberry pi yet, with native support for two cameras, vision tasks will surely strive. Convolution is a fundamental operation in many models, especially those designed for computer vision tasks. If you are familiar with some of these models, you have likely heard of Convolutional Neural Networks (CNNs), a specific class of neural networks that heavily rely on convolution operations. One critical aspect of performance evaluation for such applications is the speed of convolution operations. In this blog post, I’ll delve into the convolution speed on Raspberry Pi 5 using different implementations, aiming to provide insights into their efficiency.
Implementation
The purpose of my experiments is to compare a trivial implementation with an optimized one, using different approaches/frameworks. To simplify, I want to figure out whether it is worth optimizing my code and what speedup can one possibly expect assuming one starts with a naïve implementation. So to compare, I chose following implementations:
- Naïve implementation in C/C++ (ARMv8/Arm64)
- Naïve implementation in C/C++ optimized for speed (-o3, ARMv8/Arm64)
- OpenCV in C/C++ (ARMv8/Arm64)
- FastCV in C/C++ (ARMv7/Arm32)
Inclusion of a naive implementation is probably obvious, it takes very little time to implement, and can be typically very easy to verify in terms of (in-)correctness. It can be optimized by the compiler, assuming you don’t go wild with the used data types. OpenCV library has a highly optimized open-source implementation, that can be verified, but is much harder to read and understand if you are not expert in understanding optimisations for a particular platform. FastCV is a free Qualcomm library used to be my favorite library for basic CV algorithms that was optimized for Android and was using NEON vector instructions. It’s a shame they don’t continue to support it for ARMv8/Arm64. I include it just to compare how the speed of an efficient implementation on Arm32 compares to Arm64.
For the purpose of the comparison I convolved the one and only image of Lena. Just to make sure, I compared whether the code produces the same results. The actual source code can be found here.
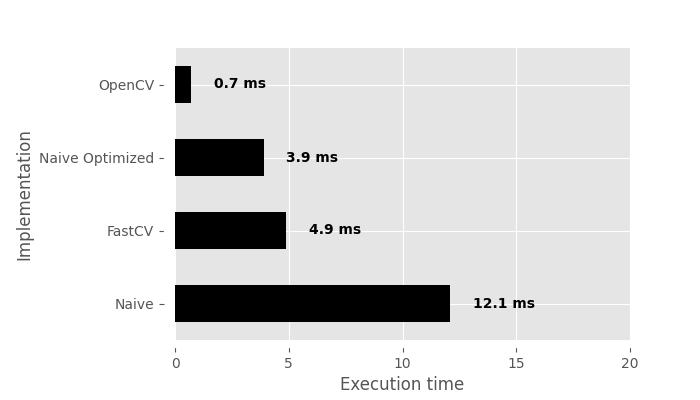
Let’s see the results:
Implementation details
For completeness here are the actual implementations/calls I used for comparison.
Naive implementation in C/C++ (that was optimized with compiler):
int convolve(const short* kernel, unsigned int kernel_rows, unsigned int kernel_cols, const uchar* src, unsigned int src_width, unsigned int src_height, unsigned int src_stride, short* tmpImg, short* dst_img, unsigned int dst_stride)
{
int i, j, m, n, sum, row_offset;
for (i = 0; i < (src_height-kernel_rows)+1; i ++) {
for (j = 0; j < (src_width-kernel_cols)+1; j++) {
sum = 0;
for (m = 0; m < kernel_rows; m++) {
row_offset = (i + m) * src_width + j;
for (n = 0; n < kernel_cols; n++) {
sum += src[row_offset + n] * kernel[m * kernel_cols + n];
}
}
dst_img[i * (src_height-kernel_rows+1) + j] = sum;
}
}
return 0;
}
...
convolve(kernel,3,3,image.data,image.cols, image.rows,0,NULL,dst,0);
...
OpenCV:
filter2D(image, destImage, -1 , kernelMatF, Point(-1, -1), 0, 0);
FastCV:
fcvFilterCorrNxNu8s16(kernel,3, 0, image.data, 512, 512, 0, dst, 0);
Discussion
It’s unsurprising that the OpenCV implementation is the fastest; however, I did not anticipate compute times below a millisecond. Particularly when compared to the FastCV implementation, which is optimized for ARM processors (albeit only for ARMv7), OpenCV is 7 times faster. Another intriguing observation is that my naive implementation, optimized for speed, is also faster than FastCV, although only by a small margin. The non-optimized version takes a bit over 12ms, which is kind of to be expected to be slow. However, I would have expected FastCV to be much faster, assuming it was well optimized. I speculate that we can attribute some credit to the GCC compiler, which seems to perform exceptionally well on an open platform like the Raspberry Pi. However, I doubt there are any specific optimizations in GCC for the Pi 5, given that it hasn’t been out for very long.
In conclusion, I highly recommend using OpenCV whenever possible. If that’s not feasible, creating your own implementation and optimizing it for speed isn’t such a bad solution. It would be interesting to compare these results with other frameworks, such as TensorFlow Lite, PyTorch, etc., in the future. Who knows, maybe in the future when needed.
12 thoughts on “Convolution Speeds on Raspberry Pi: A Simple Framework Comparison”
Comments are closed.